# Basic Concepts
# Multiprogramming
OS 用 multiprogramming 方法
- keep 多個 process 在 memory 中
- 一次只有一個 process 在 CPU 執行,其他的 process 處於 waiting 狀態
- 當執行狀態的行程必須等待資源才能往下執行(I/O request),作業系統拿回 CPU 的控制權交給等待的行程
- 目的:CPU 隨時有執行狀態的行程,使 CPU 使用率最大化
# CPU-I/O Burst Cycle
Process 基本上不是在執行 instruction,就是在執行 I/O,執行一連串的 instructions 又稱為 burst (CPU burst & I/O burst)
- 流程:process 一開始都是 CPU Burst,交由 CPU 去處理該 process,接著是 I/O Burst,做 I/O 資料的傳送
- 一般來說,多數的 CPU burst 時間很短,少部份的 CPU burst 時間很長
- I/O Bound vs. CPU Bound
- I/O Bound(I/O 密集)的 Program 通常有很多短的 CPU burst (若沒有很長的 CPU burst,則通常是 I/O Bound)
- CPU Bound(計算密集)的 Program 可能有一些很長的 CPU burst (如很長的 for loop)
這兩個狀態間一直循環,最後會呼叫一個終止行程執行的 system call 作為行程的結束
# CPU 排程決定時機
CPU scheduling 從在 ready queue 的 process 中挑選 process 進入 CPU 執行
CPU scheduling 選擇的 process 會在以下情況改變 :
- Running -> Waiting (I/O request)
- Running -> Ready (time slice 到)
- Waiting -> Ready (I/O 完成)
- Termination
# Non-preemptive 與 preemptive 法則
# Non-preemptive scheduling / Cooperative scheduling
process 一旦進入 running 狀態,除非該 process 自行放棄 CPU (I/O request or terminate),否則不會被強制中斷
- 排程器只會在以下兩種情況下被呼叫:
- Running -> Waiting (I/O request)
- Running -> Termination
- 特點:
- Simpler in design
- Poor responsiveness
- Potential hazards
# Preemptive scheduling (主流)
process 可以被強制中斷,並放回 ready queue
- 排程器在全部四種情況下都會被呼叫
- 特點:
- Higher responsiveness
- Hard to share resources race conditions
- Higher overheads
- 問題
- 共享資源的同步問題 (synchronization problem):
process 在被中斷前,可能正在使用某些共享資源,若此時被中斷並換另一個 process 執行,可能會導致共享資源的錯誤使用- 解決方法:critical section、mutex locks、semaphores、monitors
- priority inversion problem:
高優先權的 process 被低優先權的 process 所阻塞,導致無法執行- 解決方法:priority inheritance
- 共享資源的同步問題 (synchronization problem):
# Dispatcher
dispatcher 負責將 CPU 控制權交給經由 Short-term scheduler 所挑選出的 process 做以下處理:
- switching context:把現在的 process 存回 PCB,把選定的下個 process 的 PCB 資訊載入到 CPU register
- switching to user mode
- jumping to the proper location in the user program to restart that program
# Dispatcher Latency

指從 dispatcher 被呼叫要停止一個 process 並開始執行另一個 process 所需的時間
- Scheduling time
- Interrupt re-enabling time
- Context switch time
# Scheduling Algorithms
# Scheduling Criteria
- CPU utilization:理論上 0%~100%,以一顆 core 去算
- Throughput:在一個時間單位內完成的行程數量
- Turnaround time:submission ~ completion(從 ready ~ terminate 的時間)
- Waiting time:在 ready queue 的 waiting 時間
- Response time:submission ~ the first response is produced
# Algorithms
# FCFS ( First-Come, First-Served )
依 (Burst time) 抵達順序執行 (先來的先執行)
- Non-preemptive
- 最好和最糟的情況平均等待時間相差很大
![]()
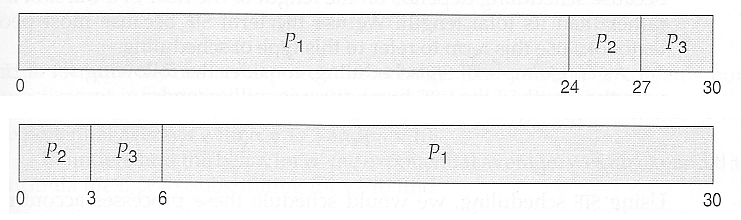
- 最糟情況:process 按照 burst time 從大到小抵達
AWT=[P (0)+P (24)+P (27)]/3=(0+24+27)/3=17 ms. - 最好情況:process 按照 burst time 從小到大抵達
AWT=[P (0)+P (3)+P (6)]/3=(0+3+6)/3=3 ms.
- 最糟情況:process 按照 burst time 從大到小抵達
- 優點
- 簡單易實作
- 公平
- 缺點
- 較長的 process 會讓後面的 process 等待很久,造成平均等待時間變長
- 低 CPU 利用度
護衛效應 (Convoy Effect)
很多 process 均在等待一個需要很長 CPU Time 來完成工作 process,造成平均等待時間大幅增加的不良現象。對 I/O-bound process 有極糟糕的影響,會造成低 I/O 利用度。
# SJF ( Shortest Job First )
短任務先做,分可插隊與不可插隊
- 運用行程下一個 CPU burst 的長度,而非 CPU burst total 長度
- 有最短的 CPU burst 的長度先得到 CPU 使用權
- Schemes
- Non-Preemptive SJF: 當一個行程拿到 CPU,不會被搶佔直到他完成
![]()
- Preemptive SJF / SRTF (Shortest Remaining Time First): 當一個新的行程抵達 ready queue 時,若該行程的 CPU burst 長度小於目前執行行程的剩餘時間,則搶佔目前執行的行程
![]()
- Non-Preemptive SJF: 當一個行程拿到 CPU,不會被搶佔直到他完成
- 優點
- average waiting time 一定最短
- SJF (non-preemptive) 若 burst all ready at 0, 則全體等待時間最短
- SRTF (preemptive) 若 任務抵達時間隨機,則全體等待時間最短
- average waiting time 一定最短
- 缺點
- 不公平
- Starvation 的問題:低優先度的 process 可能永遠無法執行
解決方法:aging,隨著等待時間增加,提升 process 的 priority


# Determining Length of Next CPU Burst
由於 SJF 的難處是在執行下一個 CPU burst 前無法得知實際的執行長度
所以 Approximate SJF 下一個 burst 可預測,為過去 CPU burst 長度的 exponential average

- = 上一次預估的 CPU Burst Time
- = 上一次實際的 CPU Burst Time
- = 此次預估的 CPU Burst Time
- = 分配比率,常用
# Priority Method
- 為更加普遍的 SJF,CPU 被分配給高優先度的行程
- 每個 process 有 priority number
- 可以為 Preemptive 或 Non-preemptive
- 優先度可由內部或外部決定
- 內部:由 OS 用某些特徵決定
- 外部:由使用者所決定
- 每個 process 有個 priority number
- 有 starvation 的問題
解決方法:aging,隨著等待時間增加,提升 process 的 priority
# Round Robin

限制 process 在 CPU 執行的時間 (time quantum),通常是 10~100 ms,達規定的執行時間後,被下一順位的 process preempted 並加到 ready queue 的尾端
- Performance
TQ Large –> 類似 FCFS
TQ small –> (context switch) 負擔加重 - turnaround 表現不好,response 表現好
- 有可能發生提早結束的情形
- 分時系統所使用的排程法
# Multilevel Queues
分成多層佇列,每層佇列分別使用自己的排班法則,同一個佇列通常放類似功能的 process
- 現在 OS 大多用這種方法
- 因為還是只有一個 queue 的程式可以執行,所以 queue 之間也有排程,常見的作法是用權重的方式隨機挑選一個出來
- Fixed priority scheduling:有 starvation 問題,若最上層的 queue 先做,下層的 process 可能一直做不到
- Time slice:每個 queue 分配一定的 CPU time
- queue 間也有 priority,每層之間不能轉移
![]()

# Multilevel Feedback Queues
process 可以在不同的 queue 中移動,因為也是一種 priority queue,也會有 starvation 的問題,通常搭配 aging 實作
- 想法:將行程依據他們的 CPU burst 特性做分類
- I/O-bound 和互動性的行程:放在較高的 priority queue –-> short CPU burst,其 cpu burst 比較短,不會佔住 cpu
- CPU-bound 行程:放在較低 priority queue –-> long CPU burst
- 三層以上的 queue
![]()
- Q0:time quantum 為 8 ms,使用 RR
- Q1:time quantum 為 16 ms,使用 RR
- Q2:FCFS
- 定義所需參數根據
- queues 數量
- 每個 queue 的排程演算法
- 提昇 / 降級一個行程的方法
- 最通用的也最複雜的 CPU 排班演算法

# 各種排程的比較

# Multi-Processor & Multi-Core Processor & Real-Time
# Multi-Processor Scheduling
# Multi-Processor Scheduling
- Asymmetric multiprocessing (AMP)
- 所有的系統活動由一個 processor 所控制,其他的 process 只處理由 master 分配的 user code
- 緩解 data sharing 的需求
- 比 SMP 簡單
- Symmetric multiprocessing (SMP)
- 每個 processor 都有自己的排程
- 所有的行程在相同的 ready queue,或每個 processor 有自己的 ready queue
- 需要同步化機制
# Processor affinity
process 與執行它的 processor 之間有 affinity 關係
- process 會將最近常使用的資料放在執行它的 processor 的快取中
- 快取的無效及資料重新放入是高成本的行為
- Solution
- soft affinity: 允許 process 在不同 processor 執行
- hard affinity: 只能在同一個 processor 執行
# NUMA and CPU Scheduling
- Non-uniform memory access (NUMA) :
![]()
NUMA(non-uniform memory access)發生在有 CPU 與 memory boards 的系統 - Real time CPU scheduling : 要求在很準確時間執行的 task (EX 火箭),不能被其他 process 影響
- soft real-time : priority 高的先處理,但無法保證高 priority 一定可以被 schedule
- hard real-time : 一定滿足條件,重點放在執行的時間
event latency : event 發生到被 serve 的這段時間
- interrupt latency : interrupt 進來後直到執行完 interrupt 的時間
- dispatch latency : 選好下個 process 到執行完 dispatch 的時間。dispatch 有可能 conflict,也就是要等別人處理完資料,花額外時間去處理 conflict
- Load-balancing
- 讓不同 processors 間的 workload 盡量平均
- 只在 processor 有 private queue 的系統下才需要
- 兩種策略(通常是平行實作)
- push migration: 將 processes 移動到閒置或 less-busy 的 processor 中
- pull migration: 閒置的 processor 將等待中的 task 從其他忙碌的 processor 中拉過來
- Load balancing 經常抵銷 processor affinity 帶來的效益

# Multi-core Processor Scheduling
# Multi-core Processor
- 更快且更少的 power 消耗
- memory stall: 當存取記憶體時,花費許多時間在等待資料 available (e.g. cache miss)
# Multi-threaded multi-core systems

- 兩個 (或更多) 的硬體 thread 被 assign 給每一個 core (i.e. Intel Hyper-threading)
- 當一個 thread 在存取記憶體時,其他 thread 就可以執行 CPU 指令
- Two ways to multithread a processor
- -grained: 當 memory stall 發生時切換到另一個 thread,因為 instruction pipeline 必須被 flush 所以成本很高
- fine-grained (interleaved): 把 pipeline 的狀態保留並切換到另一個 thread 執行,需要更多的 register 來保存資料
- Scheduling for Multi-threaded multi-core systems
- 1st level:選某個 software thread 跑在每個 hardware thread(logical processor)
![]()
- 2nd level:每個 core 去決定在哪個 hardware thread 上跑
- 1st level:選某個 software thread 跑在每個 hardware thread(logical processor)

# Real-Time Scheduling
# FCFS scheduling algorithm – Non-RTS
- T1 = (0, 4, 10) == (Ready, Execution, Period)
- T2 = (1, 2, 4)
# Rate-Monotonic (RM) algorithm

依據頻率的大小來做排程
- 更短的週期 (週期是固定的數值,在 run time 期間不會變動) –> 更高的優先度
- Fixed-priority schedule
- 同一個 task 的所有 job 都有一樣的 priority
- task 的優先度是固定的
# Earliest-Deadline-First (EDF) algorithm

Dynamic-priority scheduler
- Task’s priority 不是 fixed,由 deadline 決定
# Operating System Examples
# Solaris Scheduler
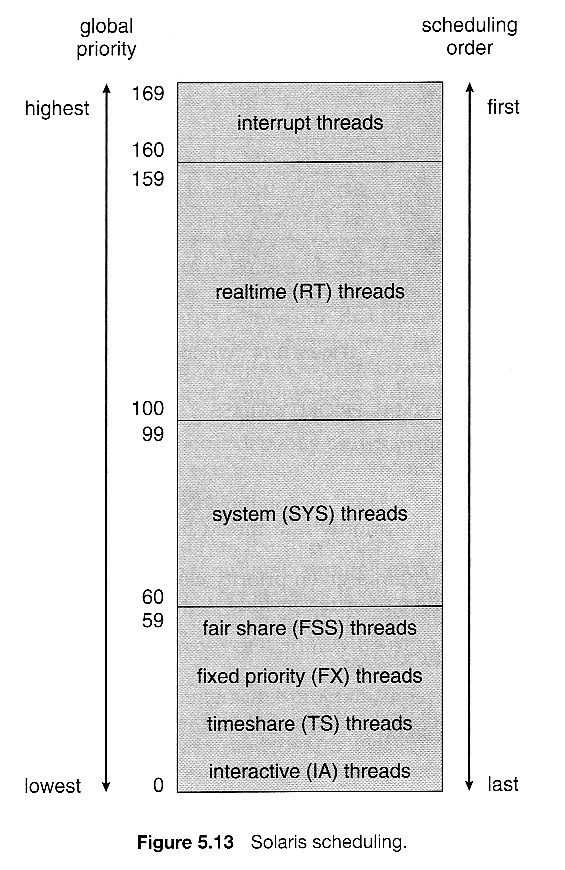
- Priority-based multilevel feedback queue scheduling
- Six classes of scheduling
- real-time
- system
- time sharing
- interactive
Solaris 9 introduced two new scheduling classes: Fixed priority and fair share
每一個類有自己的 priority & scheduling 演算法
- Scheduler 會將類的優先度轉換為 global 的優先度
# Example(time sharing, interactive)
優先度與 time slices 成反向關係,期望 CPU-bound 的 process 慢慢往下沉,I/O-bound 的 process 慢慢上浮
- Time quantum expired
- process 的 priority 降低
- 讓 CPU bound process 有機會執行
- Return from sleep
- process 的 priority 提高
- 讓 i/o bound process 優先執行
# Windows XP Scheduler

- Multilevel feedback queue scheduling
- 排程:優先度分為 0~31,由優先度最高的 queue 開始排程
- 優先度最高的 thread 永遠在執行
- 每一個 priority queue 使用 Round-robin
- 除了 Real-Time class,優先度在 run time 時期動態變更
# Linux Scheduler
- Preemptive priority based scheduling
- 只有 user mode processes 可以被 preempted
- 兩個不一樣的 process priority ranges
- 值越低優先度越高
- TQ 較高者有更高的優先度
- is a preemptive priority-based algorithm with two priority ranges
- Real-time tasks(priority range 0~99):靜態的優先度
- Other tasks(priority range 100~140):依 task 執行狀況動態決定優先度
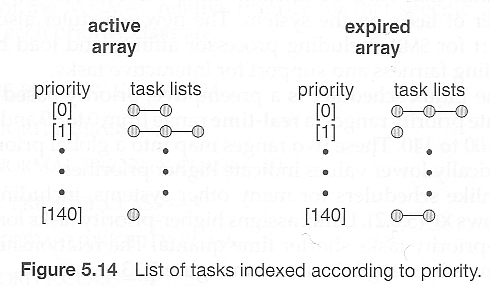
- Scheduling algorithm
![]()
- 若一個 task 還有剩餘的 TQ,都會保留在 active array,希望每一個 task 都能用完它的 TQ
- 當 task 耗盡 TQ,則為 expired 且不應被執行,移到 expired array
- task expire 後,系統會決定新的優先度以及 TQ
# Ref Notes
- Kipper’s Note
- Chang-Chia-Chi’s Note
- 陳品媛的筆記
- Mr. Opengate. OS - Ch4
