# Disk 簡介
# Disk Structure
以一個大型邏輯區段 (logical block) 的一維陣列來定址
- 以低階格式化 (low-level formatted) 的方式來選擇不同邏輯區段大小
- 對映的困難
- 大部分的磁碟會有一些損壞的磁區,但是對映會用磁碟上別處的替代備用磁區
- 有些磁碟上每一個磁軌的磁區數並不是常數
- Sectors per Track
- Constant linear velocity(CLV)
- 在 track 上的 bit 密度平均分佈
- 在 track 上外圈的 cylinder 有更多的 sector
- 保持一樣的 data rate
- 應用:CD-ROM 和 DVD-ROM
- Constant angular velocity(CAV)
- 保持一樣轉速
- 保持一樣的 data rate
- 內圈的 track 的 bit 密度高
- 應用:hard disks
- Constant linear velocity(CLV)
# 磁碟連結 (Disk Attachment)
以兩種方式存取磁碟儲存裝置
- I/O 阜 / 主機連結儲存裝置 (host-attached storage)
- 可使用 IDE、ATA、SATA、SCSI、fibre channel 等 I/O 匯流排架構
- 光纖通道 (FC,fibre channel) 有兩種變形的架構
- 儲存體區域網路 (SAN,storage-area network)
![]()
- 仲裁迴路 (FC-AL,arbitrated loop)
- 儲存體區域網路 (SAN,storage-area network)
- 網路連結儲存裝置 (network-attached storage)
![]()
- 客戶經由遠端程序呼叫的介面存取網路連結儲存體
- iSCSI 使用網路 IP 協定來實現 SCSI 協定


# Disk system

硬碟系統由多片「Disk」(磁片) 組成,每片磁片通常雙面都可存取資料。
- Disk 結構:
- 讀寫頭 (Read/Write head)
- 磁柱 (cylinder) : 不同面之相同「Track no.」組成之集合叫做「Cyclinder」
- 磁軌 (track) :每一面劃分為多個同心圓軌道,稱為「Track」
- 磁區 (sector):每條「Track」由多個「Sector」組成
- 描述磁碟幾何狀況 (C, H, S)
- C (cylinder) : 幾圈
- H (head) : 幾面(一片有兩面、最上最下面不算)
- S (sector) : 一圈幾格
Ex:
Disk system 有 10 片磁片,每片皆雙面存取,每面有 2048 條磁軌,每條磁軌有 4096 個磁區。每個磁區可以存 16 kB 資料。求 Disk system 可存放大小?
解:(10 片) x (2 面 / 片) x (2048 軌 / 面) x (4096 區 / 軌) x (16 kB / 區) = 2.5 TB
# Disk access time
- Seek time:將磁頭移至欲存取的磁軌上方所花的時間;三者中以 seek time 耗時最多,與 head 移動距離成正比,因為是機械動作
- Latency time (or Rotation time):將欲存取之磁區轉到磁頭下方所花的時間
- Transfer time:資料在磁碟與記憶體之間傳輸的時間,與傳輸量呈正比關係
# Ex1:
Disk 轉速為 7200 rpm,求平均 latency time?
解:平均 latency time = (1/2) x (60 秒 / 7200 轉) = 1/240 秒
# Ex2:
system 有 3 片磁片,雙面可存,每面有 1024 條磁軌,每條磁軌有 4096 個磁區,每個磁區可存 32 kB,轉速 6000 RPM。求 Transfer rate (每秒可傳輸多少量的資料)<Note> 每轉一圈可傳輸一個磁柱的容量
解:
Transfer rate = (3 片) x (2 面 / 片) x (4096 區 / 軌) x (32 kB / 區) x (6000 轉 / 分鐘) x (1 分鐘 / 60 秒)
# Ex3:
Disk system 有 3 片磁片雙面可存,每面有 1024 條磁軌,每條磁軌有 4096 個磁區每個磁區可存 32 kB,轉速 6000 RPM,磁碟的平均「Seek time」 = 10 ms。讀取一個大小為 2 MB 的檔案,要花多少 I/O time?
解:
- Latency time = (1/2) x (60 秒 / 6000 轉) = 5 ms
- Transfer time = (2 MB) / [ (3 片) x (2 面 / 片) x (4096 區 / 軌) x (32 kB / 區) x (6000 轉 / 分鐘) x (1 分鐘 / 60 秒) ] = 5.46 ms
I/O time = Seek time + Latency time + Transfer time = 10 ms + 5 ms + 5.46 ms
# Disk Scheduling Algorithm
目的:最小化 seek time(Seek time ≈ seek distance
- 磁碟排班演算法的選擇:
- 取決於要求的多寡與型態(只有一個要求的話,每種排班演算法都看起來像 FCFS)
- 受檔案配置方式的影響(檔案在磁碟上的位置是連續或鏈結等等)
一些 disk scheduling algorithm 常識:
- Either SSTF or LOOK is a reasonable choice for the default algorithm.
- Disk scheduling problem is inherently NP-hard. There is no optimal solution! Heuristics may be taken.
- Modern disks impose nearly the same overheads on seek and rotation.
# FCFS 演算法 (first-come, first-serve)

先到達的請求優先服務,簡單、公平、效率不佳
# SSTF 演算法 (short-seek time first)

距離目前 R/W Head 最近的 track 優先服務
- 並非最佳 (平均移動的 track 總數量無法保証為最少)
- 不公平,可能會發生 starvation(多數偏左,有一個在右邊,所以右邊的會飢餓)
# SCAN 演算法(A.k.a. elevator algorithm)

讀寫頭來回不停地掃描,若有 track 請求則服務
- 提供雙向服務
- 遇到起頭與尾端的 track 才折返
- 因為要碰到起頭或尾端才會折返,會有一些不必要的磁軌移動產生相對不公平,但不會發生 starvation
# C-SCAN 演算法

讀寫頭來回不停地掃描,若有 track 請求則服務
- 提供單向服務
- 遇到起頭與尾端的 track 才折返
# LOOK 演算法、C-LOOK 演算法

與 SCAN 極相似。唯一不同在於處理完某方向的最後一個 track 請求即折返,不需遇到 track 起頭與尾端才折返
# Disk Management
# 磁碟格式化
- 低階格式化 (low-level formatting)/ 實體格式化 (physical formatting)
- 對磁碟的每一個磁區填入一種特定的資料結構
- 通常由標頭、資料區 (通常 512Byte,但可選擇)、結尾所組成
- 包含錯誤更正碼 (ECC,error-correcting code)
- 作業系統需要紀錄它自己在磁碟上的資料結構,使用兩步驟來完成
- ** 分割 (partition)** 成一個或多個磁柱群,作業系統視每一個分割為一個分離的磁碟
- 邏輯格式化 (logical formatting):製作一個檔案系統
# 啟動區段 (boot block)

- 作業系統核心由唯讀記憶體 (ROM,read-only memory) 上的靴帶式程式載入
- 改靴帶式程式碼時需要更改 ROM 的晶片,所以 ROM 上靴帶式程式改為從硬碟上載入完整的靴帶式程式
- 完整的靴帶式程式存放在磁碟上的位置稱為啟動區段,該磁碟稱為啟動磁碟 (boot disk)/ 系統磁碟 (system disk)
- Windows 上 ROM 上的程式指示讀取主要啟動磁區 (MBR,master boot record),MBR 指示系統由哪一個分割啟動
# 毀損區段 (bad block)
- Simple disks like IDE disks
- 人工使用格式化程式去對 bad block 對應在 FAT 的 entry 做標記
- Bad blocks are locked away from allocation
- Sophisticated disks like SCSI disks
- disk controllers 維持一個 bad block 的 list
- List is updated over the life of the disk
- 或許,disk controller 修復 sector,sector 修復後,之後還能用。data 修復,與 ecc 有關
- Sector sparing(forwarding):remap bad block 到一個備用的
- 可能影響 disk-scheduling performance,會跳來跳去
- 有些備用的 spare sectors 在每個 cylinder during formatting
- Sector slipping:ships sectors all down one spot,shift 一格,shift 時間久
# 置換空間管理 (Swap-Space Management)
使用硬碟的置換空間作為記憶體的延伸
- 置換空間的大小取決於備份時所需要的量
- 太大,浪費硬碟空間
- 太小,行程不夠備份
- 置換空間的位置
- 放在檔案系統中,視為一個大型檔案
- 沒有效率,因為檔案系統的搜尋需要時間
- 檔案系統還要多於的磁碟存取
- 放在原始磁碟分割 (raw disk)
- 放在檔案系統中,視為一個大型檔案
- Linux 系統中置換的資料結構
- 每個置換區域由一系列 **4KB 分頁槽 (page slot)** 組成
- 置換對映圖 (swap map):連結每一個置換區域的整數計數器陣列
- 計數器數值表示置換分頁對映到的行程
# RAID
獨立磁碟冗餘陣列 (RAID, Redundant Array of Independent Disks) 簡稱磁碟陣列,由多顆磁碟機組成一個陣列,將資料以分段 (striping) 的方式同時對不同的磁碟做讀寫的動作。 使用 RAID 有以下目的:
-
提升可靠度:provides reliability via redundancy.
-
增進效能:improving performance by means of parallelism.
-
RAID 的兩個重要特性
- 不昂貴 (I,inexpensive):以前 RAID 由小型便宜的磁碟機組成,被視為大型昂貴磁碟機的替代品
- 獨立 (I,independent):現在 RAID 被使用是因為他們的高可靠度和較高的資料傳送速率
-
藉由 ** 重複 (redundancy)** 改進可靠度
- 假設一台磁碟機的平均失效時間 (mean time to failure) 為 100000 小時,100 台磁碟機陣列中某一台磁碟機的平均失效時間 100000/100 = 1000 小時
- 鏡射 (mirrored volume)
- 複製磁碟
- 每次寫入都會在兩台磁碟機一起執行,兩台同時壞掉資料才會遺失
- 假設一台的修復時間為 10 小時,平均資料遺失時間為 (100000)²/(2* 10)
- 加入 ** 非揮發性 RAM (NVRAM,nonvolatile RAM)** 快取到 RAID 陣列,在電源失效時保護資料遺失
-
透過平行化提昇效能
- 資料分割 (data striping) 的最簡單格式是將每一個位元組分成為源分散在許多台磁碟機,這種分割稱為位元層次的分割 (bit-level striping)
- 將檔案第 i 個位元寫到第 i 個磁碟機中
- 有 i 台磁碟機,則視為 i 被大小且 i 被存取速率的磁碟機
- 也可在區段層次分割 (block-level striping)
- 將第 n 個區段放在第 n 台磁碟機
- 資料分割 (data striping) 的最簡單格式是將每一個位元組分成為源分散在許多台磁碟機,這種分割稱為位元層次的分割 (bit-level striping)
# RAID level
RAID 把多個硬碟組合成為一個邏輯磁區,因此 OS 只會把它當作一個硬碟。
RAID 被排成不同的 level
- Striping
- Mirror(Replication 複製)
- Error-correcting code(ECC) & Parity bit
RAID Level 高低不完全代表系統效能或可靠度的高低,端視管理員的需求
# RAID 0:Striping/Span
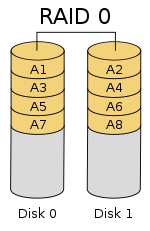
兩個以上的磁碟並聯起來成為一個大容量的磁碟,將資料切割存放到多部硬碟中且不會重複存放
- non-redundant striping
- 優點:效能改善,可進行平行讀寫,適用於具有高效能需求的系統
理論上,硬碟越多效能就等於 [單一硬碟效能]×[硬碟數]。事實上受限於匯流排 I/O 瓶頸及其它硬體因素的影響,RAID 效能會隨邊際遞減。
- 缺點:完全沒有容錯能力
# RAID 1:Mirroring

RAID 1 會將資料同時寫入兩個或多個磁碟,形成「鏡像」。每個磁碟都保存完整的資料副本
- 讀取效能會提升。系統可以同時從多顆磁碟讀取資料
- 寫入效能不會提升。因為每次寫入都必須同步到所有鏡像磁碟,速度受限於單一磁碟的寫入速度
- 優點:系統可靠度很高,極佳的資料安全性,實作容易
- 缺點:效率最差,且需花費兩倍的成本
# RAID 0+1:Mirror + Striping
結合了 RAID 0 與 RAID 1 兩種模式。至少要 4 顆以上的磁碟,且硬碟總數需為偶數
- 優點:擁有 RAID 1 容錯力,以及 RAID 0 整體讀寫速度
- 缺點:成本很高,一次最少要用上 4 顆硬碟,且也要浪費一半的總容量
# RAID 2:Hamming Code

以 ** 漢明碼(Hamming Code)** 的方式將資料進行編碼後分割為獨立的位元,資料分別寫入硬碟中,具錯誤檢查與更正能力,當一部硬碟壞掉時,可由其它硬碟的內容來更正
- 在資料中加入了錯誤修正碼
- recover 任何單一個 disk failure
可以偵測兩個 disk 的錯誤(i.e. bits),但只能訂正一個 bit 的錯誤 - 優點:空間有效率比 RAID 1 好(75% overhead)
例如:Hamming code (7,4)
- 4 data bits (on 4 disks) + 3 parity bits (on 3 disks)
- Each parity bit is linear code of 3 data bits
# RAID 3:Parallel with Parity

多利用一顆磁碟儲存同位元資訊達到容錯功能
- Bit-level striping
- 通過編碼再將資料位元分割後分別存在硬碟中,而將同位元檢查後單獨存在一個硬碟中
- 當硬碟有問題,可由同位元檢測得知
- 優點:所需的硬碟數較 RAID 2 節省
- 缺點:不是個好方法,因為全部的 disk 都不斷被寫 (Bit-interleaving),效能低落
# RAID 4:Parallel with Parity (block)

跟 RAID 3 相同,不過其支援的資料交插是以 block 為單位計算的
- Block-level striping
- 每次的資料存取都必須從同位元檢查的那個硬碟中取出對應的同位元資料進行核對
- 優點:更好的空間效率(33% overhead)
- 缺點:
- 計算與儲存 parity bit 的 cost
- P-disk 不斷被寫,效能瓶頸
# RAID 5:Striping with Rotating Parity

RAID 5 是一種儲存效能、資料安全和儲存成本兼顧的儲存解決方案,有較多的商業應用
- Distributed Parity
- 分散 data & parity 在所有的 disks,避免過度使用單一個 disk(e.g. RAID 3,4)
- 當 RAID 5 的一個磁碟資料發生損壞後,可以利用剩下的資料和相應的奇偶校驗資訊去恢復被損壞的資料
- 與 RAID 4 雷同,但是 RAID 5 把同位元分散依序儲存於陣列中的每顆磁碟內,改善了 P-disk 不斷被寫的效能瓶頸
# Read BW
增加 N 倍,因為所有四個 disks 可以服務一個 read request
# Write BW

- Method1
- read out all unmodified (N-2) data bits.
- re-compute parity bit.
- write both modified bit and parity bit to disks.
–-> write BW = N / ((N-2)+2) = 1 –-> remains the same
- Method2
- only read the parity bit and modified bit.
- re-compute parity bit by the difference.
- write both modified bit and parity bit.
–-> write BW = N / (2+2) = N/4 times faster
# RAID 6:Read Solomon Code

RAID 6 增加第 2 個獨立的奇偶校驗資訊塊。容許 2 個硬碟同時損壞,至少必須具備 4 或 4 個以上硬碟才能生效
- P+Q Dual Parity Redundancy
- 增加第二個獨立的奇偶校驗資訊塊,提高可靠性
- 使用 ECC code(i.e. Error Correction Code)而不是單一個 parity bit
- Parity bits are also striped across disks
- 與 RAID 5 雷同,但是儲存額外的 redundant information 去防止多個 disk failure
- RAID 6 在硬體磁碟陣列卡的功能中,也是最常見的磁碟陣列等級
# Hybrid RAID
- RAID 0+1:Stripe then replicate
![]()
- RAID 1+0:Replicate then stripe
![]()


# Ref Notes
- Kipper’s Note
- Chang-Chia-Chi’s Note
- 陳品媛的筆記
- Mr. Opengate. OS - Ch10
- WillyWangkaa’s Note
